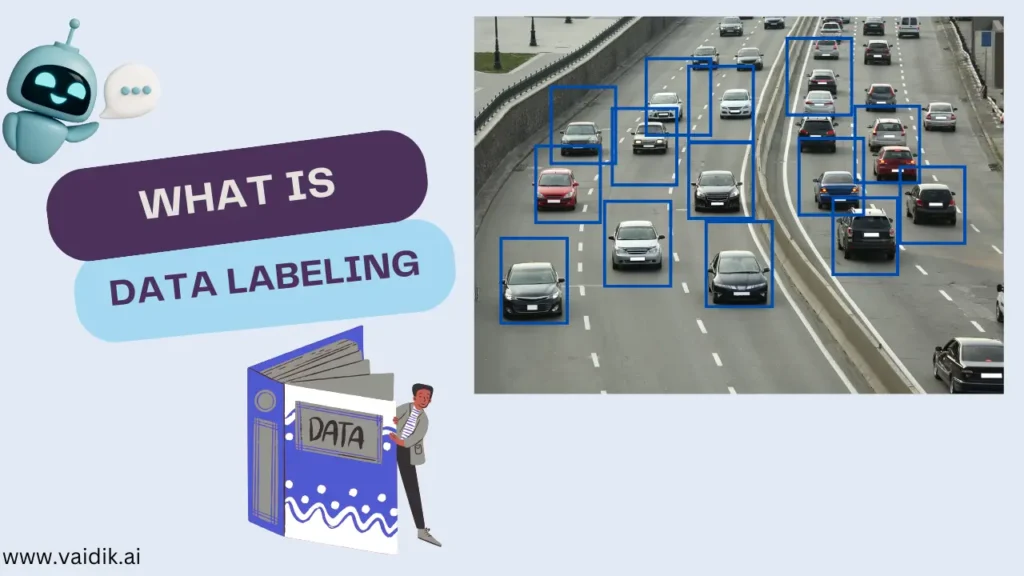
In the data-centric era, which enables many slick and advanced technologies like AI and ML to work, most of them fundamentally rely on vast amounts of datasets. However, raw data is rarely in an appropriate form for such applications.
This is where the process of data labeling proves essential. Data labeling is the process of adding labels to raw data, such as text, images, videos, or audio, so that machines can understand them. The output of labeled data serves as the basis for training machine learning models so that they could recognize patterns and predict the outputs.
Importance of Data Labeling
Machine learning models learn through examples. They require data where situations are labeled to clearly identify patterns, relationships, and structures. Without good-quality labeled data, the model cannot perform tasks accurately. For instance,
In a picture recognition scenario, an annotated dataset may contain pictures that have been labeled as “cat” or “dog,” which can help the model differentiate between the two classes.
In NLP, labeled datasets might include sentences annotated with parts of speech, named entities, or sentiment classifications.
Data labeling is important because it:
- Improves comprehension: It ensures that the model understands the dataset by linking each data point to relevant knowledge.
- Increases precision: Quality labeled data ensures better models.
- Facilitates diverse applications: From self-driving cars to healthcare diagnostics, labeled data is vital for training models across various sectors.
Categories of Data Labeling
- Image Annotation
Image labeling encompasses the tagging of images with metadata to prepare models for tasks such as object detection, facial recognition, and image segmentation. Techniques employed include:
Bounding boxes: Drawing rectangles around objects within an image.
Semantic segmentation: Assigning a label to each pixel in an image.
Landmark annotation: Identifying significant points in an image, such as facial features.
- Text Annotation
This process involves tagging textual data for applications in NLP. Common types of text annotation include:
Sentiment analysis: Categorizing text based on emotional tone.
Entity recognition involves the identification of names, locations, or organizations within a given text. Text classification refers to the process of categorizing a document, such as distinguishing between spam and non-spam emails.
- Audio Annotation
Audio annotation is also significant in applications, such as speech recognition and language translation. Some of the techniques used are as follows:
Transcription: Translating speech into text.
Speaker identification: Labelling audio segments by speaker.
Sound classification: Labeling different types of sounds like laughter or ambient noise.
- Video Annotation
This process involves integrating both image and temporal annotations for model training for activities such as motion tracking and activity recognition. Some of the techniques used are as follows:
Object tracking: Identifying moving objects across video frames.
Event tagging: Annotating particular events in a video timeline, for example, traffic violations or customer interactions.
The Data Labeling Process
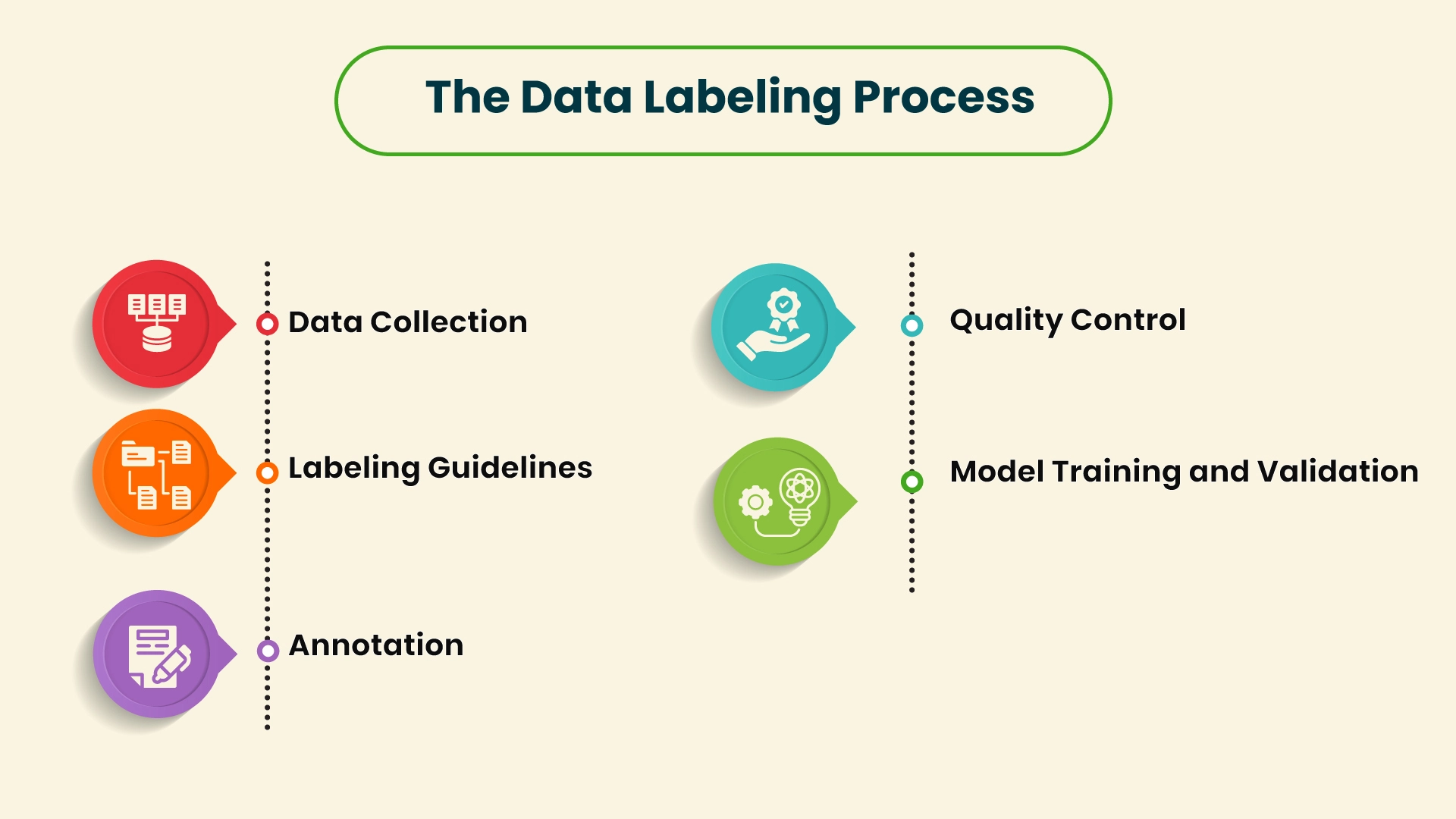
Data labeling involves the following general steps to ensure accuracy and relevance in the annotations:
- Data Collection
It begins with data collection, which may involve images, audio files, videos, or text documents obtained from different origins.
- Labeling Guidelines
Establishing a broad set of rules is important for consistency in annotations. For example, the defining characteristics that make a “cat” different from a “dog” will help the labelers use the same standards.
- Annotation
Human annotators or automated systems apply the established labels to the dataset. In cases requiring subjective judgment, such as sentiment analysis, human participation is essential.
- Quality Control
The labeled data undergoes a review process to verify accuracy and consistency. Multiple annotators may evaluate the same data points to rectify any errors.
- Model Training and Validation
Labeled data is used for training a machine-learning model. Validation processes check the model’s performance to ensure it matches expectations, with adjustments as necessary.
Difficulties in Data Labeling
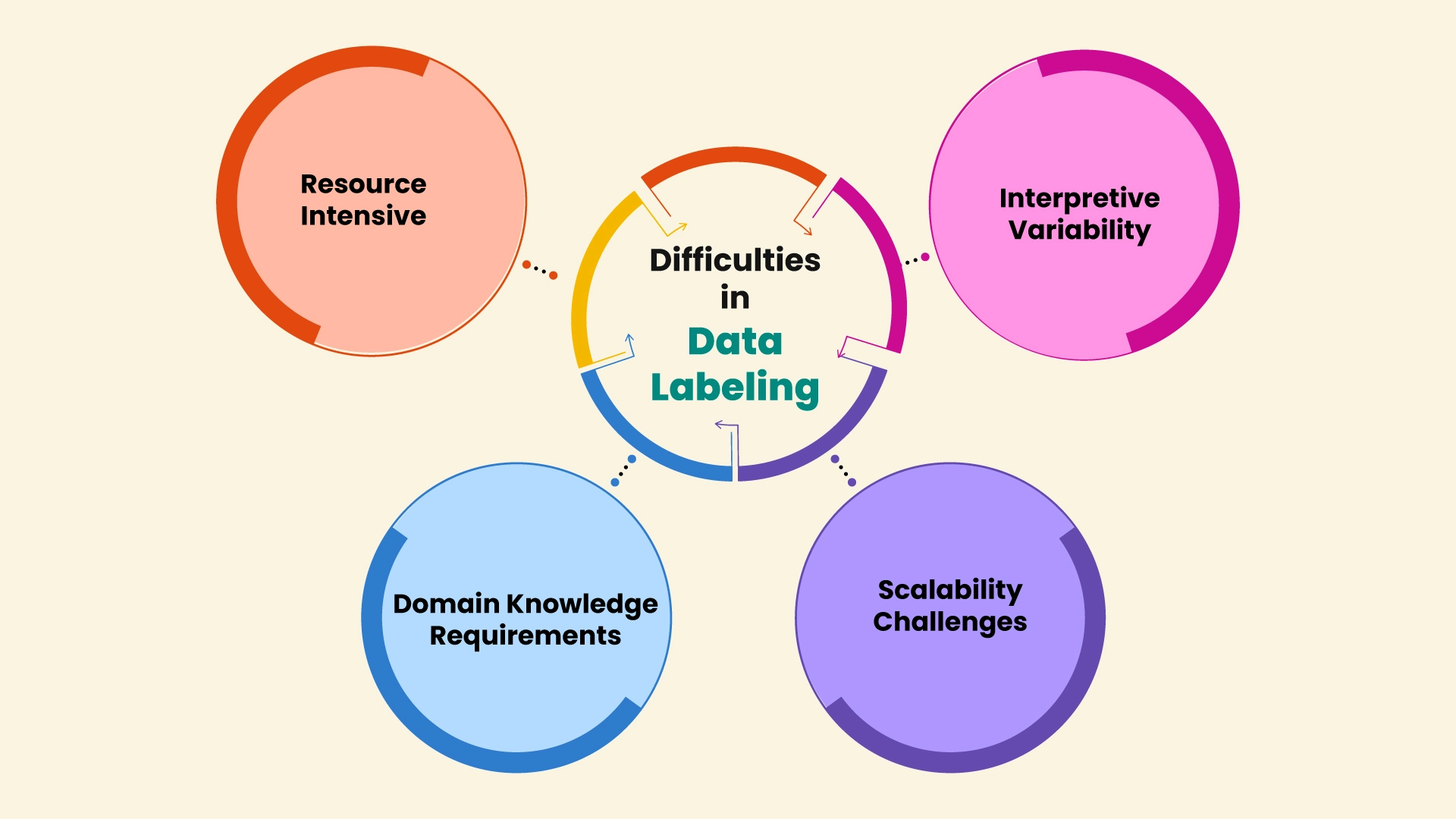
Data labeling is vital but is coupled with several difficulties:
- Resource Intensive
Extensive datasets may require considerable amounts of time and monetary resources to label, especially in more complex tasks such as semantic segmentation or transcription.
- Interpretive Variability
Certain tasks, such as sentiment analysis, depend on subjective interpretation, leading to inconsistent annotations.
- Scalability Challenges
The larger the volume of data, the more challenging it is to scale without degrading the quality of the labeling process.
- Domain Knowledge Requirements
Certain labeling tasks, such as medical images, require domain knowledge and thus limit the pool of qualified annotators.
Tools And Technologies for Data Labeling
To solve the issues, a number of tools and technologies were designed to enhance the speed at which data can be labeled.
- Manual Annotation Tools
Tools such as Labelbox, RectLabel, and VGG Image Annotator allow humans to label different kinds of data through an easy-to-use interface by annotating them manually.
- Automated Annotation Solutions
AI-based tools include Amazon SageMaker Ground Truth and Google AutoML, used to automate particular tasks that involve labeling to minimize human interaction.
- Crowdsourcing Solutions
Organizations can outsource labeling tasks to a global workforce through platforms like Amazon Mechanical Turk and Appen.
- Active Learning Techniques
Active learning algorithms target the most uncertain data points, thus streamlining the labeling process and improving model accuracy.
Applications of Data Annotation
Data annotation plays a vital role in various artificial intelligence (AI) and machine learning (ML) applications, such as:
- Autonomous Vehicles
Annotated datasets are essential for training models to identify pedestrians, vehicles, traffic signs, and other critical components, facilitating safe navigation.
- Healthcare
In the realm of medical imaging, labeled scans are utilized to train models for detecting diseases, including the identification of tumors or fractures.
- E-commerce
Labeled product images and user comments improve recommendations as well as opinion analysis.
- Content Moderation
Most social media websites require labeled data for the purpose of detecting harmful content, spam, and other misinformation campaigns.
- Virtual Assistants
Digital assistants, such as Siri and Alexa, rely on the labeled audio as well as text data in understanding and giving users answers.
Importance of Human-in-the-Loop Systems
Although great automation milestones have been recorded, it still requires a human-in-the-loop system for accurate data annotation. Human intelligence merged with the machine’s pace guarantees precision. Take the example:
Machines will do tasks, such as box placement. It is a repetitive process that only needs humans for error inspection and correction-mostly subjective or hard annotations. Such an approach strikes the perfect balance between scalability and precision.
Trends of Future Data Annotation
- Synthetic Data
The development of synthetically labeled data can reduce reliance on labor-intensive labeling processes.
- Self-Training
Popular models that can make sense of information from unlabeled data may lower the need to label exhaustively.
- Domain-Specific Tools
Emerging specialized annotation tools for application domains such as healthcare and finance are making possible more efficient and effective annotation
- Improved Quality Control
AI-driven quality assurance mechanisms can detect inconsistencies and errors within labeled datasets, thereby ensuring greater accuracy.
Conclusion
Data labeling serves as the foundation for artificial intelligence and machine learning technologies. It connects raw data with intelligent systems, enabling transformative applications across various industries. Despite existing challenges, ongoing advancements in tools, techniques, and methodologies are enhancing the efficiency and accessibility of data labeling.
As artificial intelligence continues to progress, the significance of data labeling will also grow, solidifying its position as a fundamental element of technological advancement. Whether in the context of training autonomous vehicles or enhancing medical diagnostics, data labeling remains crucial in shaping the future of intelligent systems.
Although the process may require significant time and resources, recent advancements in automation, tools, and methodologies are enhancing its scalability and efficiency. The incorporation of human expertise via human-in-the-loop systems guarantees high-quality annotations, especially for intricate or subjective tasks.
As artificial intelligence technologies advance, the necessity for accurately labeled data will continue to increase, underscoring the importance of developing better techniques and tools. Data labeling serves not only to connect raw data with intelligent applications but also plays a crucial role in influencing the future of AI-driven solutions, thereby fostering progress and innovation worldwide.